Indexing Methods:
We will go through an array of indexing techniques and cover both the 'how' and 'when' of applying these methods, ensuring optimal data linkage.
The Record Linkage Toolkit is a Python library that provides tools for linking records within or between data sources. It offers data cleaning and standardisation, indexing, and comparison functionalities.
AGENT has created a differentially private version of the Record Linkage library, op_recordlinkage.
Often, critical insights lie at the intersection of multiple datasets, possibly managed by different stewards or even external entities. This is where Record Linkage allows us to connect multiple datasets without compromising privacy. Here we will look at two key aspects of the Record Linkage library
Indexing Methods:
We will go through an array of indexing techniques and cover both the 'how' and 'when' of applying these methods, ensuring optimal data linkage.
Comparison rules:
We will share different compare rules.
To use the op_recordlinkage, you need to import the library as presented in the following code block:
%%ag
import op_recordlinkage
You can use the following mock dataset with these examples to better understand the various options available:
import recordlinkage as rl
from recordlinkage.datasets import load_febrl4
import pandas as pd
import networkx as nx
import seaborn as sns
import matplotlib.pyplot as plt
dfA = {
'ID':[i for i in range(5)],
'names':['john','james','arthur','raj','kenny'],
'country':['england','usa','england','india','usa'],
}
dfB = {
'ID':[i for i in range(6,11)],
'names':['jon','arthur','mathew','raj','keny'],
'country':['england','ireland','england','india','usa']
}
dfA = pd.DataFrame(dfA).set_index('ID')
dfB = pd.DataFrame(dfB).set_index('ID')
large_dfA , large_dfB = load_febrl4()
# moving the data into the AGENT environment
session.private_import(name='dfA' ,data=dfA)
session.private_import(name='dfB',data=dfB)
session.private_import(name='large_dfA',data=large_dfA)
session.private_import(name='large_dfB',data=large_dfB)
The indexing module is used to create pairs of records. These pairs are known as candidate links or candidate matches. Several indexing algorithms, such as full, random, blocking, and sorted neighbourhood indexing, are used for both linking and deduplication purposes.
Benefits of using indexing:
Efficiency:
Without indexing, the process would involve comparing every record in one dataset with every record in another dataset (or with all other records in the same dataset for deduplication). This can be computationally intensive. Indexing reduces the number of comparisons by eliminating obvious non-matches.
Accuracy:
Some indexing methods, especially those that take advantage of specific data characteristics, can improve the quality of candidate links by focusing on more probable matches.
Scalability:
For large datasets, indexing is almost a necessity. It allows the record linkage process to be feasible even with millions of records.
How Indexing Should Be Done:
Before choosing an indexing method, it's crucial to understand the characteristics of your data. For instance, do you have a unique identifier? Are there common fields that can be used for blocking?
Not all indexing methods are suitable for all types of data. For instance, blocking might be more efficient when there's a common field between datasets, while sorted neighbourhood indexing can be better for datasets with slight variations in values.
It's better to have fewer high-quality candidate links than numerous low-quality ones. Adjust the parameters of your indexing method to ensure that the candidates are probable matches.
Indexing is often an iterative process. As you test and refine your linkage strategy, you may need to adjust your indexing method or parameters to improve results.
Full indexing, often termed as "full cartesian product indexing", creates candidate links by forming all possible unique combinations between records in one dataset and those in another dataset. Essentially, every record in the first dataset is compared to every record in the second dataset.
When to Use It:
Small Datasets:
Full indexing is most feasible and practical when both datasets are relatively small. Given its exhaustive nature, the number of comparisons grows significantly with the size of the datasets.
Absence of Common Attributes:
When datasets lack distinct common attributes that can be used for more efficient indexing methods like blocking or sorted neighbourhood indexing, full indexing might be the most straightforward approach.
Maximising Match Opportunities:
Full indexing ensures that no potential matches are overlooked. This makes it ideal when aiming for completeness of potential matches, regardless of computational cost.
%%ag
import op_recordlinkage as rl
indexer = rl.Index()
indexer.full()
links = indexer.index(pdfA,pdfB)
ag_print(f"Total number of links in full indexing : {links.count(eps=1)}")
Block indexing, often simply referred to as "blocking", is an indexing method used in record linkage. In this method, records are partitioned into distinct groups or "blocks", based on one or more key attributes. Only records within the same block are compared, thus significantly reducing the number of comparisons required. The key attribute(s) used for blocking should have a high probability of being the same for true matches.
When to Use It:
Large Datasets:
Blocking is particularly effective when dealing with large datasets. By reducing the number of comparisons, blocking makes the linkage process more scalable and efficient.
Common Key Attributes:
Blocking is suitable when there's a common field or attribute across the datasets that is likely to be consistent for true matches, such as postal code, birth year, or initial letters of a name.
Balance Between Efficiency and Completeness:
While blocking greatly improves efficiency, it may miss some true matches if they are in different blocks. Thus, it's ideal when seeking a balance between computational efficiency and match completeness.
%%ag
import op_recordlinkage as rl
indexer = rl.Index()
indexer.block('names','names')
links = indexer.index(pdfA,pdfB)
ag_print(f"Total number of links in block indexing : {links.count(eps=1)}")
Adding more blocking rules allows you to obtain more potential candidate links based on the new rule and increases the number of pairs satisfying either of the block rules.
%%ag
import op_recordlinkage as rl
indexer = rl.Index()
indexer.block('country','country')
indexer.block('names','names')
links = indexer.index(pdfA,pdfB)
ag_print(f"Total number of links in block indexing : {links.count(eps=1)}")
Sorted-neighbourhood indexing is a method used in record linkage, especially when dealing with noisy data or slight variations in data entries. In this approach, records are first sorted based on a specific key attribute. Once sorted, a window of a specified size slides through the sorted list. Only records that fall within this window are considered as candidate pairs for comparison. This method assumes that true matches are likely to be near each other in the sorted order, even if they aren't exactly identical due to errors or variations.
When to Use It:
Noisy Data:
Sorted-neighbourhood indexing is particularly effective when data has inconsistencies, such as minor spelling variations, typographical errors, or abbreviations. Traditional blocking might fail to group such near-matches together, but they are likely to be close in a sorted list.
Unknown Errors and Variations:
If you're unsure about the types and extents of errors in your dataset, sorted-neighbourhood indexing can be a safer bet than simple blocking, since it accommodates slight variations in the key attribute.
Balancing Efficiency and Completeness:
While the sorted-neighborhood method can lead to more comparisons than simple blocking (depending on the window size), it can be less exhaustive than full indexing. It provides a balance between efficiency and the risk of missing potential matches.
Adaptable Window Size:
The window size can be adjusted based on the quality of data and desired trade-off between computational cost and likelihood of capturing matches. A larger window will capture more potential matches but will also require more comparisons.
%%ag
import op_recordlinkage as rl
indexer = rl.Index()
indexer.sortedneighbourhood('names','names')
links = indexer.index(pdfA,pdfB)
ag_print(f"Total number of links using sorted neighbourhood: {links.count(eps=1)}")
Random indexing is a method used in record linkage where pairs of records are selected at random to form candidate links. Instead of performing exhaustive comparisons or using structured rules (as in blocking or sorted-neighbourhood methods), this method relies on random sampling to generate a subset of potential matches. It offers a stochastic approach to the problem of identifying candidate record pairs.
When to Use It:
Exploratory Analysis:
If you're initially trying to gauge the quality of matches between two datasets without diving deep into detailed comparisons, random indexing can give you a quick, albeit approximate, view.
Large Datasets:
When dealing with exceedingly large datasets, even efficient methods like blocking might be computationally intensive. Random indexing can provide a quick way to generate a subset of candidate links for preliminary analysis.
Absence of Clear Blocking Key:
If the datasets do not have clear attributes for blocking or if the quality of data is uncertain, random indexing can serve as a starting point before deciding on more structured approaches.
Balancing Computational Cost:
While random indexing might miss many potential matches, it allows for a reduction in computational cost. It's a trade-off between efficiency and completeness.
Benchmarking:
Random indexing can be used as a baseline method to benchmark the effectiveness of other more sophisticated record linkage methods.
%%ag
import op_recordlinkage as rl
indexer = rl.Index()
indexer.random(n = 10)
links = indexer.index(pdfA,pdfB)
ag_print(f"Total number of links in random indexing : {links.count(eps=1)}")
Comparing refers to the process of assessing pairs of records to determine how similar they are across various attributes or fields. Once potential candidate pairs are identified (using methods like blocking, sorted-neighbourhood indexing, or full indexing), these pairs undergo a comparison to produce a similarity score. This score is then used to decide if the pair is a true match or not.
The comparison can involve:
Checking if the values in the fields are exactly the same.
Using algorithms to determine the similarity between values. This is especially useful for textual data where typos or different representations might exist (e.g., "Jon" vs. "John").
For numeric or date fields, differences can be computed directly or categorizsd into bands (e.g., age difference of less than 5 years, between 5 and 10 years, etc.).
Depending on domain-specific knowledge, custom comparison functions can be employed. For example, in a medical context, two different codes might represent the same condition, and a custom function can identify them as a match.
Comparing is a crucial step in record linkage as it directly influences the quality of the linkage. Accurate comparisons ensure that true matches are identified while minimising false positives (incorrectly identified matches) and false negatives (missed true matches).
We start by setting up an indexing rule to generate candidate links on which we can further filter using various comparison rules.
%%ag
import op_recordlinkage as rl
# Applying block indexing against some of the
indexer = rl.Index()
indexer.block(left_on='date_of_birth',right_on='date_of_birth')
indexer.block(left_on='postcode',right_on='postcode')
links = indexer.index(large_pdfA,large_pdfB)
ag_print(f"Total number of candidate links = {links.count(eps=0.1)}")
The exact compare rule in record linkage refers to a method where two fields or attributes from different records are compared to determine if they are exactly the same. This means that the values must match character for character, with no deviations. If the two fields are identical, the comparison yields a match; otherwise, it does not.
When to Use It:
High-Quality Data:
When you're confident about the consistency and accuracy of the data, and there's no room for typos, abbreviations, or variations.
Unique Identifiers:
For fields that contain unique identifiers such as Social Security Numbers, employee IDs, or product codes. In these cases, even a single character difference indicates distinct entities.
Binary or Categorical Data:
Fields with a limited set of values, like gender (Male/Female) or a Yes/No flag.
Consistent Formatting:
When you're certain that data formats are consistent across datasets, such as date fields always being in the "YYYY-MM-DD" format.
Performance Considerations:
Exact matching is typically faster than fuzzy matching, so if computational efficiency is a concern and the data's nature permits, exact matching can be a good choice.
%%ag
compare = rl.Compare()
compare.exact(left_on='soc_sec_id',right_on='soc_sec_id',label='social_compare')
compare.exact(left_on='given_name',right_on='given_name',label='name_compare')
compare.exact(left_on='address_1',right_on='address_1',label='address_compare')
features = compare.compute(links,large_pdfA,large_pdfB)
ag_print(features.mean(eps=1))
| Rule | Description | Use Case |
|---|---|---|
jaro | Measures the similarity between two strings. It accounts for characters in common and the number of transpositions between the two strings. | Effective for shorter strings, such as names. |
jarowinkler | An extension of the Jaro similarity metric. It's more favourable to strings that match from the beginning. A prefix scale is applied which gives more favourable ratings to strings that match from the start. | Especially beneficial for personal names where prefixes can be crucial. |
levenshtein | Calculates the minimum number of single-character edits (i.e., insertions, deletions, or substitutions) to change one word into the other. | Useful for fields that might have minor typos or misspellings. |
damerau_levenshtein | A variant of the Levenshtein distance. It allows transpositions (switches of two adjacent characters) alongside the usual edits. | Efficient for capturing common typing errors where two neighboring characters are accidentally swapped. |
titqgramle | The Q-gram method divides strings into overlapping substrings of length q (often 2, called bigrams). The similarity score then relies on the count of shared q-grams between the two strings. | Suitable for longer text fields, capturing more contextual similarities. |
cosine | Cosine similarity measures the cosine of the angle between two vectors. In the context of text, these vectors can be formed by term frequency (like bag-of-words). | Effective for comparing longer texts or when the order of words isn't critical. |
smith_waterman | A local sequence alignment method that identifies the optimal local alignments by ignoring the more divergent sections. | Suitable when comparing sequences where parts of the sequence are believed to be more relevant than the entirety. |
lcs | Measures the longest sequence of characters that are common between two strings without considering the positions of characters in terms of the entire string. | Useful when there are substrings in common, but scattered throughout the string. |
When choosing a string similarity algorithm, the nature of the data and the specific application play critical roles. To get optimal matching results, it's often beneficial to experiment with various algorithms and even combine them, adjusting their weights.
%%ag
compare = rl.Compare()
compare.string(left_on='address_1',right_on='address_1',label='address',method='cosine')
compare.string(left_on='given_name',right_on='given_name',label='name',method='jaro')
features = compare.compute(links,large_pdfA,large_pdfB)
Once the features matrix is computed, we can obtain the linked dataframe using a threshold value. Any link with sum of all features having value greater than the threshold will be used for creating the merged dataframe. The linked dataset will have columns with prefix as l_ and r_ for the first and second dataset using for linking respectively.
%%ag
compare = rl.Compare()
compare.string(left_on='address_1',right_on='address_1',label='address',method='cosine')
compare.string(left_on='given_name',right_on='given_name',label='name',method='jaro')
features = compare.compute(links,large_pdfA,large_pdfB)
# Lets find the mean value of the sum of all weights assigned on each compare rule.
ag_print(features.mean(eps=0.1).sum())
Based on the above value , a threshold roughly = 1.5 should be a very strong link. You can check it by running the following code
%%ag
linked_df = compare.get_match(1.5)
ag_print(linked_df.describe(eps=1))
This class is used to compare numeric values.
| Rule | Description |
|---|---|
Step Function ('step') | This function assigns a similarity of 1 if the absolute difference between two numbers is less than a specified offset. Otherwise, it assigns a similarity of 0. It's a sharp cutoff, meaning that small deviations in the numeric values can yield a similarity of 0. |
Linear Function ('linear') | The similarity decreases linearly with the absolute difference between two numbers. The function starts at 1 (for identical values) and linearly decreases to 0 as the difference increases. You can control the rate of decline by adjusting the scale parameter. |
Exponential Function ('exp') | This function decreases the similarity exponentially based on the absolute difference between two numbers. The rate of decrease can be controlled by the scale parameter. |
Gaussian Function ('gauss') | The similarity is calculated based on the Gaussian (normal) distribution. The function gives a similarity of 1 for identical values, and the similarity diminishes in a bell curve manner as the difference increases. |
Squared Function ('squared') | Similar to the exponential function, but the decrease in similarity is based on the square of the difference between two numbers. |
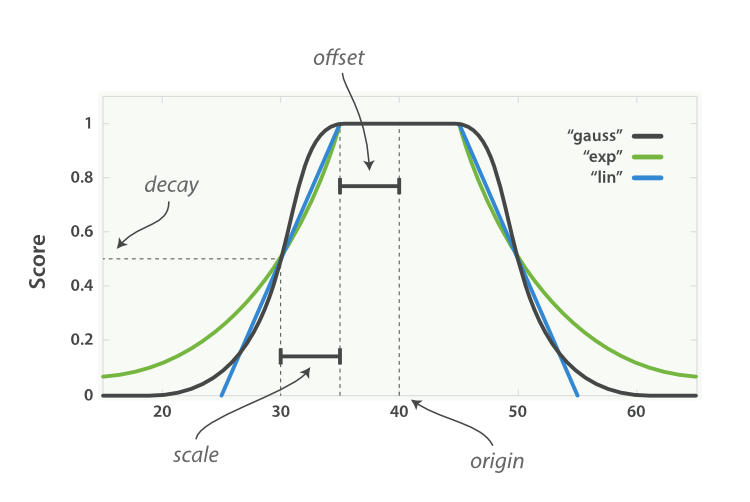
Parameters to be aware of:
Defines the absolute difference below which two numbers are considered similar (for the step function).
Controls the rate of decline in similarity for the linear, exponential, and Gaussian functions.
The center of the similarity function. For the step function, it defines the point at which the similarity drops from 1 to 0.
The value to assign when a comparison involves a missing value.
The recordlinkage.compare.geo() is designed to evaluate the similarity between two geographic locations specified by their WGS84 coordinates (latitude and longitude). This method takes into account the Earth's curvature and computes the haversine distance, which calculates the shortest distance between two points on the surface of a sphere. This makes it suitable for comparing real-world geographical coordinates.
The similarity algorithms are ‘step’, ‘linear’, ‘exp’, ‘gauss’ or ‘squared’. The similarity functions are the same as in recordlinkage.Compare.numeric()
The recordlinkage.compare.date() is devised to compute the similarity between two date values, especially focusing on common errors and discrepancies observed in date records. These discrepancies can be due to human errors, typos, or certain automated data entry systems.
Key Features:
Handling Month-Day Swap:
The class can account for situations where the day and month in a date might have been swapped, which is a common mistake in data entry.
Handling Month Number Translation Errors:
The class can also handle errors that arise when months are translated into numbers. For instance, mistakenly translating "October" as "9" instead of "10".
You can find all methods and guides provided by the op_recordlinkage library by accessing the Record Linkage API reference.
The following is a list of helpful resources when using the op_recordlinkage library.